The robots.txt file is used to control what content search engines are allowed to access on your site. This is great for controlling duplicate content and for directing your crawl budget to your most important pages. It is important to understand that if you you have content that you want to remove from Google’s index, disallowing the content in your robots.txt will only prevent Google from accessing it again, it will not remove the content from the index – to do this you’ll need to use the noindex tag.I’m good, let’s skip ahead to how to use robots.txt wildcards
Also worth noting is that Google makes the categorical statement that most people don’t need to worry about crawl budget:
First, we’d like to emphasize that crawl budget, as described below, is not something most publishers have to worry about. If new pages tend to be crawled the same day they’re published, crawl budget is not something webmasters need to focus on. Likewise, if a site has fewer than a few thousand URLs, most of the time it will be crawled efficiently.
While the above may be true for most websites, it is likely not true for any website that is big enough to hire an SEO – notice in their statement Google says that you don’t need to worry about crawl budget… if your site is less than a few thousand URLs…. Crawl budget is a significant factor that should be considered to ensure that you are focusing crawl resources on pages that are important.
The use of robots.txt wildcards is very important for effectively controlling how search engines crawl. While typical formatting in robots.txt will prevent the crawling of the pages in a directory or a specific URL, using wildcards in your robots.txt file will allow you to prevent search engines from accessing content based on patterns in URLs – such as a parameter or the repetition of a character. Before diving into the details of how to use wildcards in robots.txt, let’s take a minute to review the robots.txt basics (I’m good, let’s skip ahead to how to use robots.txt wildcards).
Robots.txt Basics
If we want to allow all search engines to access everything on the site there are three ways to do this: with the Disallow: , Allow: /, or by simply leaving the robots.txt file empty. Any of these will allow search engines to do whatever they want on your site.
User-agent: * Disallow:
or
User-agent: * Allow: /
Conversely, if you would like to prevent search engines from accessing any content on your site, you would use the Disallow: / command. This is great for dev sites and sites that are being built out which you don’t want to allow search engines access to yet but you almost never want this command on your live site.
User-agent: * Disallow: /
If you want to allow specific search engines different access, you can use the user-agent command to do this. In the above examples, we simply say “user-agent: * ” which means all search engines should obey the following commands. The example below allows Google to access the entire site while Yandex is not permitted to access anything.
User-agent: Googlebot Disallow: User-agent: Yandex: Disallow: /
In order to prevent crawling of a directory, simply specify the directory rather than the root, /.
User-agent: * Disallow: /directory/
How to Use Wildcards in Robots.txt
Ok, now that we’ve covered why you would want to use robots.txt wildcards and a few basic robots.txt examples, let’s dive into how to use robots.txt wildcards. There are a couple things we need to know about using a wildcard in robots.txt up front. The first is that you don’t need to append a wildcard to every string in your robots.txt. It is implied that if you block /directory-z/, you want to block everything in this directory and do not need to include a wildcard (such as /directory-z/*). The second thing you need to know is that there are actually two different types of wildcards supported by Google:
* wildcards
The * wildcard character will simply match any sequence of characters. This is useful whenever there are clear URL patterns that you want to disallow such as filters and parameters.
$ wildcards
The $ wildcard character is used to denote the end of a URL. This is useful for matching specific file types, such as .pdf.
Below are several common use cases for robots.txt wildcards:
Block search engines from accessing any URL that has a ? in it:
User-agent: * Disallow: /*?
Block search engines from crawling any URL a search results page (query?kw=)
User-agent: * Disallow: /query?kw=*
Block search engines from crawling any URL url with the ?color= parameter in it, except for ?color=blue
User-agent: * Disallow: /*?color Allow: /*?color=blue
Block search engines from crawling comment feeds in WordPress
User-agent: * Disallow: /comments/feed/
Block search engines from crawling URLs in a common child directory
User-agent: * Disallow: /*/child/
Block search engines from crawling URLs in a specific directory which 3 or more dashes
User-agent: * Disallow: /directory/*-*-*-
Block search engines from crawling any URL that ends with “.pdf” – Note, if there are parameters appended to the URL, this wildcard will not prevent crawling since the URL no longer ends with “.pdf”
User-agent: * Disallow: /*.pdf$
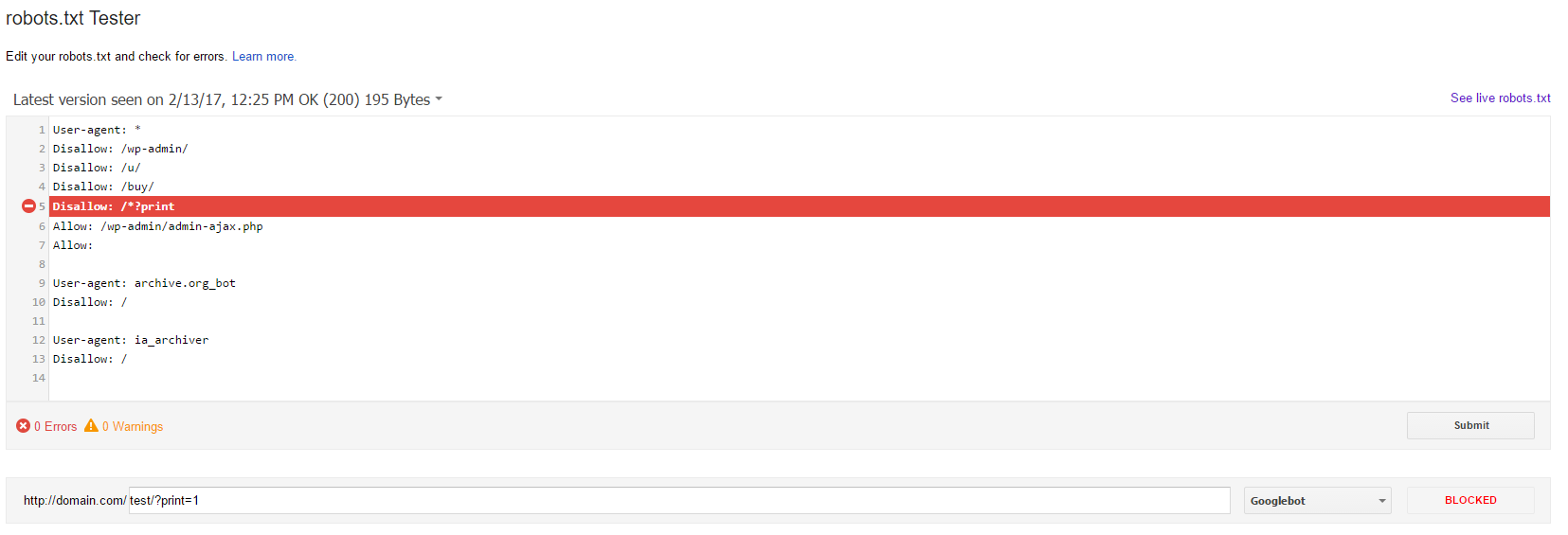
Always Validate your Robots.txt Wildcards Before Pushing Live
It is always a good idea to double check your robots.txt wildcards before flipping the switch and making any updates to your live robots.txt file. Since simply adding a / to your robots.txt file could potentially prevent search engines from indexing your entire site, there is no margin of error. Mistakes can be catastrophic and can have long recovery times. The best way to double check your work is to use Google’s Robots.txt Testing Tool.