If you’ve needed to extract information from a website, and ended up copy and pasting data from the webpage to your spreadsheet, you probably should have been scraping anything that took more than 2 minutes. Scraping a website is particularly useful if you need information in mass – such as scraping a competitor to find gaps and opportunities. There are several different methods for scraping data and while there are advantages and disadvantages to each one, the methods aren’t better or worse, just different. So if you’re trying to figure out how to scrape a website, your method depends on 1) whether you are a developer and 2) what you need to scrape.
How to Scrape a Website: Methods
I am a marketer, not a developer. I’m writing this for other non-developers. This means I’m not going to show you how to write a script to scrape webpages but am going to show you different tools that can be used to scrape sites and efficiently get the data you need. If you’re a developer and need to do a lot of scraping, you’ll probably end up writing your own scripts.
The next qualification for figuring out how to scrape a website is 2) what you need to scrape. Do you need to scrape:
- A list of 1,000 links off one or two pages?
- The same element off of a list of 50 pages
- The same element off as many pages as possible on a website
For each of the scenarios above, different tools can be used to scrape and collect data.
Scraper (Scrape Similar)
Scraper is a Google Chrome extension that allows you to easily pull other similar things from a given page. Scraper is a great solution for pulling similar items off of a given page or two. It doesn’t scale really well but it’s super easy and quick to use. In this case, we’ll say that we want to get this list of cities in California from Wikipedia.
To start you’ll need to have the Scraper extension already installed. Then pull up the list on Wikipedia. Right click on the first town and select “scrape similar”.
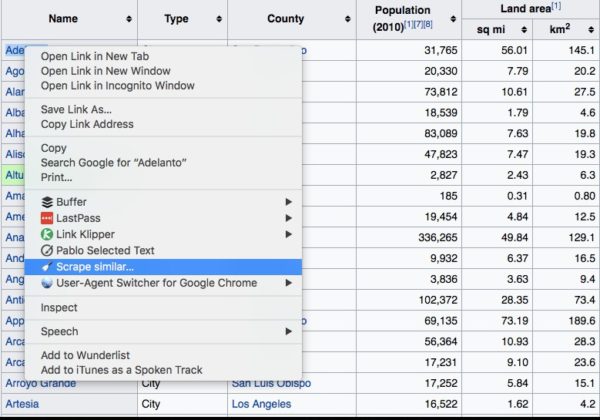
This will bring up the scraper dialog box where all of the “similar” elements will be displayed and you can select whether you want to export to a file or copy and paste.
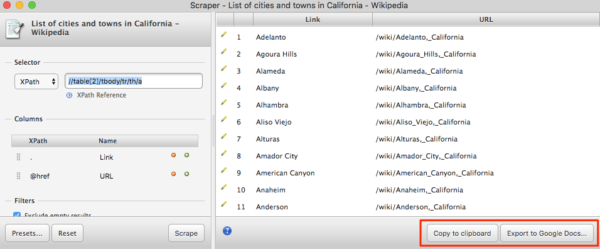
Note: depending on whether you are scraping an element in a table or an element that has css applied, you may need to edit the scraping selector. If Scraper comes up short, you may notice numbers (ex: [1]) in this input field or elements like <span> that need to be removed. This can happen when you are trying to scrape an entire list of objects and scraper will hyper focus on the specific element – such as the first <li> in the list. Playing around with the selector field should allow you to properly refine the list so that you get what you’re looking for.
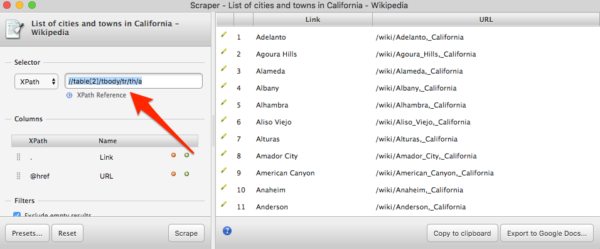
If the list of data that you want to collect is a set of links (such as the list of sites on the first page of Google, or even the list of cities in California as in this example), the Link Klipper chrome plugin might be a good solution. All you have to do is right click and drag your mouse over the links you want to download. You don’t have to monkey around at all with figuring out the proper xpath selectors. This will only work on a set of links though.
Xpath & GoogleSheets
If you have a small list of predefined webpages that you want to collect data from, using Xpath in Google Sheets may be the optimal solution. Small means up to a couple hundred. Google sheets will often lose it if you try to scrape data in mass. This will pull your data faster than using Scraper on each individual page, but it often requires more detailed xpath setup. If you have a really small list of pages and are bad at Xpath, you may just want to use Scraper on each individual page.
For this project, let’s work the the four URLs below.
https://geoffkenyon.com/free-template-google-data-studio-seo-dashboard/
https://geoffkenyon.com/how-to-create-xml-sitemaps/
https://geoffkenyon.com/angularjs-seo-crawling/
https://geoffkenyon.com/how-to-use-wildcards-robots-txt/
You can view all of the following Xpath scraping functions in the following Google Sheets doc:
https://docs.google.com/spreadsheets/d/1-mJ7sEr3NbLDyWksa-H4M9M1X9KEAclaNiRgpZwPBt0/edit?usp=sharing
In Google Sheets, you can use the =importXML function to scrape data from a webpage and import it into your Google Sheet.
Scraping the Title with Xpath
Since the <title> is it’s own element, it is one of the simplest elements to scrape with Xpath. Below is formula you can use the scrape the <title> element from a URL and pull it into Xpath.
=importxml("url","//title")
Since we title is it’s own element, we can simply reference the element, we don’t have to specify any additional classes. You can use a cell reference such as a2 instead of a specific “url”.
Scraping the H1 Tag
Provided that there is only 1 H1 tag on a page, you can use a similar formula as above:
=IMPORTXML(A2,"//div/h1")
If there are multiple H1 tags and we want to scrape a specific H1 tag, you can specify a specific class or id:
=importxml(A2,"//h1[@id='comments']")
How to Scrape Anything…. With Screaming Frog
Both of the scraping methods above have their uses, but simply, they are not a good solution for many situations including:
- Scraping several different pieces of data from a page
- Scraping an unknown set of pages – such as crawling a site to find all of a competitor’s site and scrape the SEO text they have on a page
- Checking whether or not an item is present on a page – such as whether your analytics code is present
Fortunately, there are more scalable scraping solutions that will help us accomplish these goals. If you are not a developer and aren’t able to write your own scripts, this means you’ll have to use a software program to scrape websites in scale. If you’re looking for a free solution, you’re pretty much out of luck. For large scale website scraping projects, you’re going to need to pay to play.
My prefered solution is Screaming Frog SEO Spider. While it was originally designed to scrape specific SEO elements from a page, it has evolved into a very capable scraping software solution that is able to crawl a website (or a given list of URLs) and extract almost anything you want. One of the best parts about Screaming Frog, if you’re utilizing the crawling functionality, is that you can restrict the crawler to only crawl certain pages, thus allowing you to crawl a larger set of pages before maxing out your memory.
For this example, let’s say that we want to scrape the SEO text at the bottom of Bass Pro’s category pages.
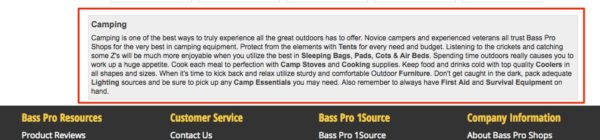
URL: http://www.basspro.com/Camping/_/T-12325000000
To start your scraping journey, start by firing up Google Chrome and going to the URL that you want to scrape. Then right click on the text you want to scrape and click “inspect element”. Then right click on the <p> element for the text you want to copy and then select copy > copy xpath.
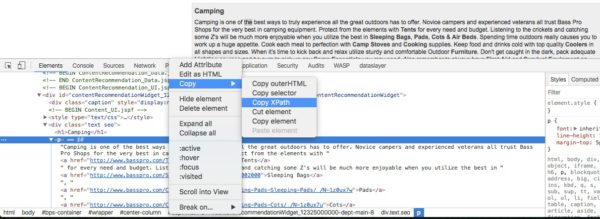
Once you’ve copied your xpath, fire up screaming frog, then navigate to “configuration” > “custom” > “extraction”.
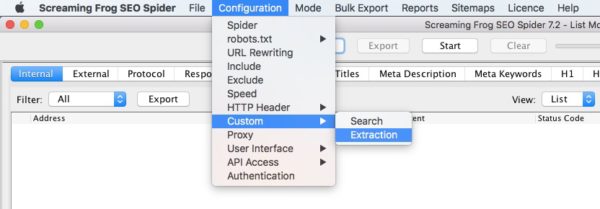
Now, change the first “inactive” scraper to “xpath” and name your custom extraction. Then you can paste in the xpath that you just copied into the extraction field. Finally, change what you will extract from “Extract Inner HTML” to “Extract Text”.

The next step in scraping text from the website is to test this out on a single URL. Change Screaming From from “Crawl” mode to “List” mode.
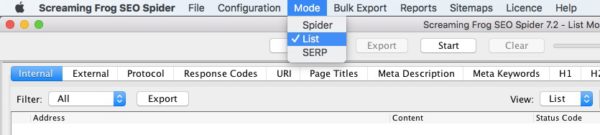
Now copy and paste the URL you were initially working off of into the screaming frog list mode and start crawling. Once Screaming Frog has finished crawling this URL, you should be able to view the “custom” tab, change to “extraction” and view the text you’ve scraped from the website.

Once you’ve confirmed that Screaming Frog is scraping the webpages properly for the correct data, you should be good to go. At this point, you can change from “List” mode to “Crawl” mode. This will set Screaming Frog to crawl the entire site rather than a specific set of URLs. Now you should be able to crawl your competitors site and scrape data from their pages for your competitive advantage.