How much do you know about Google’s invisible watermarking they put on images, text, video, and audio files that Gemini / Vertex AI generates? It’s called SynthID. If you’re using AI in your content / asset generation process, this is probably helpful to understand SynthID (and inherently how invisible watermarking works). Think about this:
Why is SynthID important?
As AI generated content fills the web, provenance, or being able to show the source of the content becomes really important – Think about the importance of providing originality of content featuring politicians, for example. SynthID gives Google a hidden fingerprint on everything created by Gemini.
Bringing it home for SEOs, if Google can fingerprint and detect AI generated content at an infrastructure level, why would they surface it in organic results when they could force users into AI Mode instead (think Google flights, maps, local, etc). If LLMs can fingerprint their own content and detect other AI generated content, why would they cite your AI content instead of another resource that is more likely human created?
Two other big reasons this is important:
- It’s super important to be able to understand if content is original or AI generated (beyond the implications for search)
- Training LLMs on LLM output creates a circular training pattern.
What is SynthID
SynthId is Google’s way of fingerprinting text, images, video, and sounds made by Google’s Gemini / Vertex AI platforms. It is an invisible watermark woven into the content in the generation process to allow Google to identify content made from AI efficiently at scale.
SynthID’s EXIF Data
The first step in the fingerprinting process is the EXIF image data. When Gemini / Vertex generates an image, they attach meta data that says Google AI created this image. Google is adding a provenance chain with every Gemini image. The metadata says the image is AI generated and inserts proof of creation, creator, and a seal.
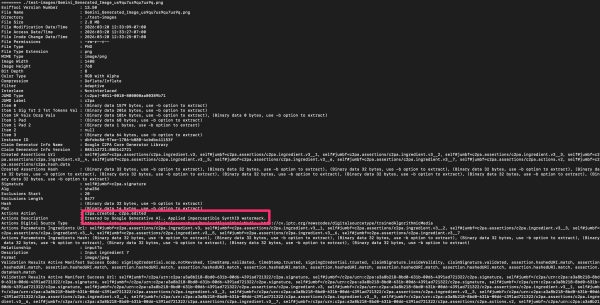
Here’s a breakdown of relevant meta data included in the EXIF:
| Field | What it means |
|---|---|
| JUMD Type / Label | Identifies this as a C2PA (Coalition for Content Provenance and Authenticity) created images; the industry standard for content provenance |
| Instance ID | Unique ID for this image – Gemini generated images gets their own ID |
| Claim Generator Info Name | The software that created the provenance claim; Google C2PA Core Generator Library |
| Claim Generator Info Version | Version of Google’s C2PA library used |
| Actions Action | What happened to create this image: c2pa.created (generated from scratch) and c2pa.edited (post processing applied) |
| Actions Description | The plain English description: “Created by Google Generative AI” and “Applied imperceptible SynthID watermark” |
| Actions Digital Source Type | Formal classification: trainedAlgorithmicMedia – IPTC standard code meaning it was made by a trained AI model |
| Alg / Hash | SHA-256 hash ensuring the manifest hasn’t been tampered with. If someone modifies the image, the hash breaks |
| Signature | Cryptographic signature from Google proving this manifest is authentic and was issued by them |
| Item 1 Sig Tst / OCSP Vals | Timestamp token and certificate revocation check. Proves when the signature was created and that Google’s signing certificate was valid at that time |
| Validation Results | A checklist of integrity checks that all passed: signing credential not revoked, timestamp valid, signature trusted, all assertions match their hashes |
| Relationship: parentOf | This image is the “parent” / the original, not a derivative of something else |
| Created Assertions / Ingredients | References to the input data (prompts, seed images) that went into generating this image |
*C2PA stands for The Coalition for Content Provenance and Authenticity (C2PA) and is an open standard for content, declaring the creator, authenticity, and edits. It embeds a cryptographic seal on the image, video, or audio with the intent of showing what content was made by AI.
This is just the start because all of this metadata gets stripped when someone screenshots the image, re-saves it in a different format, or uploads it to most social media platforms (they typically strip out EXIF data). SynthID is woven into the image and will survive meta data removal.
How SynthID Works
SynthID is an undetectable pattern woven into the pixel data during generation. It survives cropping, compression, screenshots, and a lot of editing. Think of it as pixels in an image that you can only see if you know where to look and have the right key to decode. The pixels in the pattern have color values that are slightly shifted from their “original color” such that it’s imperceptible to humans, but it creates a noticeable pattern for machines.
It is added to images during the generation process and exists only in specific spatial frequencies across the image to create consistent patterns of pixel variation at particular scales and angles. For example, one carrier frequency might be a diagonal stripe pattern that repeats at a specific interval. SynthID embeds its fingerprint by creating these patterns simultaneously across the image which is why it survives cropping.
This is done in limited quantities to avoid adding too much “noise” to the photo, otherwise the overall quality is degraded to the point that people notice.
The SynthID watermark pattern is based on a seed hash – which determines which pattern is generated across the whole image. Each image gets a unique pattern that is decodable by Google.
How to Detect Synth ID with Saturation
I lied to you a little – you can actually see this watermark under some conditions. It is more and less evident on specific images. The image here is a plain white image Gemini generated and I then cranked up the saturation (1000x) – the pixels with different color values become evident
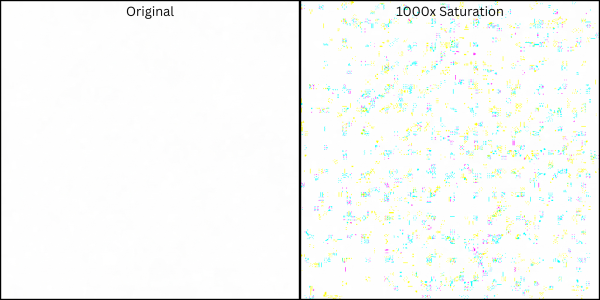
Saturation reveals the pixels and “noise”, but by isolating the specific frequencies where SynthID exists reveals a clearer pattern. The image below is the white square with the SynthID frequencies isolated, and then saturated the RGB channels, the pattern becomes more vivid and evident:

The hidden pattern becomes visible as a colored lattice overlaying the image.
On images other than plain white backgrounds, the pattern exists but is less evident, but is still there – and can still be picked up by Google. The first photo below was created by Gemini while I took the second photo. When we turn up the saturation to 1000x, you can see that on the Gemini photo, the noise texture is everywhere and relatively consistent – this is the SynthID. On my photo, the noise primarily follows the cliffs


If we isolate the same frequencies and saturate, we see the pattern is much more consistent and pronounced in the Gemini image than the photo.


Since we don’t have the key to decode, our interpretations won’t be nearly as precise and evaluations would likely have a fair amount of false positives due to the complexity and randomness of actual images (not plain-white squares). Google has the encoder and decoder, and know the carrier frequencies, the patterns, and the per-image seed that determines each unique watermark.
Does SynthID hurt SEO and GEO?
I’ve been experimenting with visual and programmatic detection methods, and the implications for SEO and GEO strategy are significant. If you’re building content strategies that involve AI-generated imagery (or any AI generated content types), this is worth understanding now rather than later.
What’s old is new. Spintax was machine-generated content that worked until Google could detect it at scale. SynthID is literally the detection infrastructure for the AI content era.
If Google can identify AI-generated content at the infrastructure level, they can make decisions about how (or whether) to surface it. Think about that in the context of the Helpful Content system and their stated goal of rewarding original, experience-based content.
For GEO, LLMs training on AI-generated content creates a feedback loop – sometimes called model collapse. When this happens, it narrows the output distribution over generations creating more homogenous models and the diversity of outputs degrades.This is the opposite of what Google wants (remember: Google’s information gain scoring patent).
Watermarking like SynthID (OpenAI and Meta have their own watermarking research programs) gives models a way to filter AI generated content out of future training sets at scale.
I’m not saying don’t create content with AI, but before you go full bore, you should understand this and mitigate risk accordingly. If you’re taking the easy path now, it might work for a while, but looking at the long arc of SEO, it will certainly stop working at some point.