
Simply put, duplicate content is any content that is identical to another page on your site OR a different site on the web. While this might not sound like a big deal, it can actually be quite problematic for search engines (and inherently you). When search engines come across duplicate content, it’s difficult for them to decide which page to display in search results. Typically search engines will try to choose the original or canonical version of the content though they often do not get this right, leading to the wrong page ranking in search results.
Why Duplicate Content is so Bad
While this isn’t that bad (you’re still ranking, right?), this is just the tip of the iceberg for duplicate content. There are several other issues created by duplicate content. The first may appear minor, but it has a significant impact on user experience. Say that you get a few links to a URL that has sorting parameters in it and Googlebot determines that it’s the most authoritative version of your content. Users who click that search result won’t immediately see all of your products nor your well thought out landing page. Instead of http://site.com/hiking-shoes, they see http://site.com/hiking-shoes/?color=black&size=10/. This isn’t the best experience and you’ll likely see people bouncing at a higher than normal rate.
Secondly, if you have many pages created by sorting, tracking, session ID’s and the like, you waste Googlebot’s time crawling your site. You don’t want to waste crawling bandwidth on duplicate content, you want all of your unique landing pages and other valuable content indexed and shown in search results. While this isn’t as big of a problem as it used to be for Google when Googlebot tended to crawl a fewer set number of pages on your site, it’s not a good idea to give Google the runaround and have them crawling preventable duplicate content.
Another reason duplicate content hurts, is that it dilutes the value of your link. If someone links to the page via a URL with tracking or sorting parameters, these links are actually pointing to different URLs. This causes a dilution in link equity and dampens the ability of the correct page from ranking.
And finally, we get to penalties. While there is no penalty for having duplicate content (Google typically just filters duplicate content out of their index instead), duplicate content can lead to a penalty. Duplicate content is one of the signs Google uses to identify low quality sites, if you have a lot of duplicate content, you can find yourself in the cross hairs of the Panda algorithm, which can demolish your traffic. So despite there not being an actual duplicate content penalty, duplicate content is one of the key flags for Panda and we should go to lengths to minimize duplicate content.
Sources of Duplicate Content
Duplicate content often happens for technical reasons. There are several reasons why you might be discovering duplicate content on your site.
URL Parameters
Odds are you’re using some sort of URL based parameters. While these parameters can add a lot of value and yield very useful data, they can also create a lot of duplicate content. Some of the most common URL Parameters are:
- Tracking (UTM) parameters – these are often associated with analytics tracking and can help you track the effectiveness of different marketing channels.
- Ecommerce parameters – these come in many different forms but sorting/filtering parameters are the most common ones we see.
- Session ID’s – while most sites use cookies for session ID’s you can still come across session ID’s in URLs.
- Pagination parameters – depending on how your site handles pagination, this can be a big cause of parameter based duplicate content.

Transient Categories
On some sites, especially ecommerce sites, you’ll find that the category associated with a page can change based on how the user navigates. For example – if a user clicked through a navigation from appliances > kitchen > refrigerators, the URL might look like /appliances/kitchen/refrigerators. But if the user clicked from kitchen > appliances > refrigerators, the URL would be /kitchen/appliances/refrigerators.
Similarly, you have to be familiar with how your platform handles pages that can be associated with multiple categories. Some systems will allow a page to show up under many different categories. For example a saw could show up under /saws/, /power-tools/, or /milwaulkee/ (brand name).
Both of these examples are common sources of duplicate content to check for.
Printer Friendly Versions
While this capability is nice for users, but Googlebot will often find the printer-friendly page if it is accessible. It’s exactly the same page, just different formatting with a different URL. While it might be printer friendly, it’s not Google friendly.
WWW versus Non-WWW
If both versions of your site are available, which one should Google show? It’s important that you choose one version and enforce it as Google considers both of these different versions of the same page even though a user understands they are the same.
HTTPS versus HTTP
As with the www and non-www version of your site, search engines consider both the http and https versions of your site to be different versions. If you have secure pages, make sure that you are only able to load either the secure or non-secure version of the page.
Often this becomes a problem when a site only has a few pages that are secure (such as a contact page) and uses relative URLs in the source code. In this circumstance, it is easy for crawlers to access a duplicate secure version of the entire site.
Scraping
If you have a popular site, it’s not unheard of for your content to be “scraped” (in laymen’s terms: copied) without attribution. Google then has to choose between the two sites. While Google often gets this right, there are many instances where the copied version ranks higher in search results. Scraping is a content problem with both ecommerce and content sites.
How to Find Duplicate Content
Nothing compares to the simplicity of copying and pasting a snippet of text into a Google search. Of course there are plenty of tools to help you deal with large duplicate content issues too.
Google Search Console (Google Webmaster Tools)
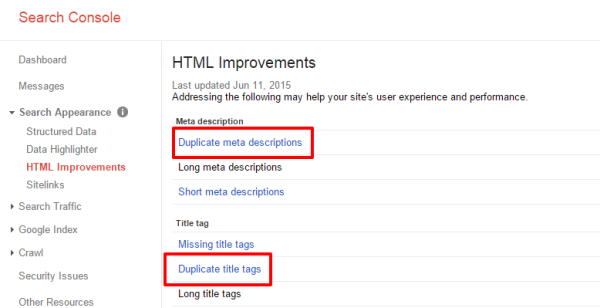
There’s no better answer than one from the horse’s mouth. Fortunately, in Google Webmaster Tools (or Google Search Console as it’s recently been renamed) you can find a list of duplicate page titles and meta descriptions. While this doesn’t actually provide a list of duplicate pages, you can find a pretty good list of pages that are likely duplicates and weed them out yourself. To view the report, navigate to Search Appearance>HTML Improvements and you’ll see a links to duplicate meta descriptions and duplicate titles.
Search Operators
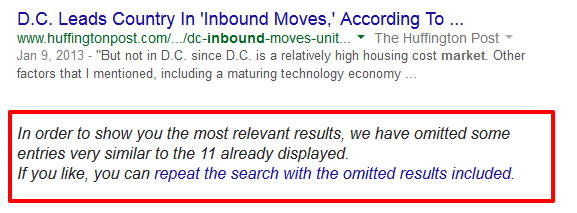
These tools can be really helpful for seeing specific duplicates. Use site:mysite.com and intitle:”keyword” (example) to find all the instances on your domain that contain that keyword in the title. You can also just use the intitle search across the web to see if Google is weeding out any other duplicates.
Pro Tip: Make sure to look through the omitted search results
Moz Pro
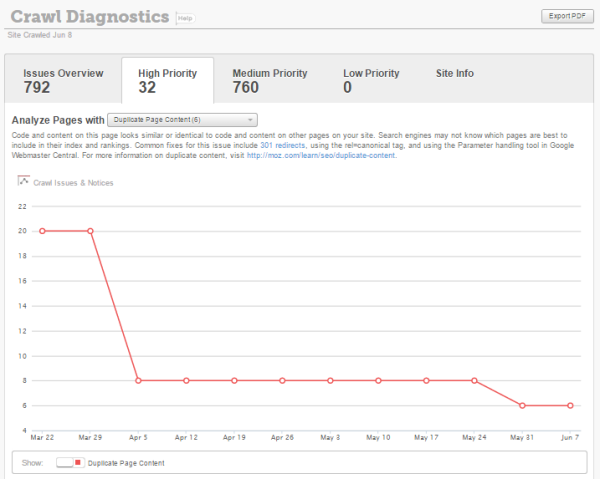
Another easy way to identify duplicate content is to review your crawl diagnostics in the Moz Pro App. Conveniently, they have a duplicate page content report which you can download to create a list of your duplicate content pages.
How to Get Rid of Duplicate Content
While it might seem like a large undertaking to fix all of your duplicate content, it can have a big payoff and it is worth the effort. Cleaning up your duplicate content can often result in a significant uptick in your organic traffic. The good news is that you have several tools at your disposal to combat duplicate content. Here’s how to fix your duplicate content issues:
Rel=”canonical”
This will allow you to choose one page that you want displayed in search results. Take the URL of the chosen page and add <link href=“http://mysite.com/chosen-page/” rel=“canonical”/> in to the <head> section of all the duplicate pages. This points all the duplicates towards canonical version and lets the Googlebot know which page is a duplicate and which one should be included in search results. You can find documentation on the canonical tag on Google and on Moz.
![]()
301 Redirects
A 301 redirect works similar to the canonical. The difference is that while the Rel=”canonical” tag allows duplicates pages to be visible to users, a 301 redirect takes users and search bots to the chosen page. You should always use a 301 redirect to:
- Force the www or non-www version of your site
- Force the http:// or https:// version of your site
- Enforce proper capitalization in your URLs
- Remove old content and send users to new content
You can verify your redirects are 301s with this tool from SEO Book.

Noindex
Adding <meta name=”robots” content=”noindex”> to the duplicate page will prevent search bots from indexing that page, also preventing the duplicate page to be displayed in search results. This is really impactful for fixing taxonomy generated duplicate content – often category and tag pages can have the noindex command automatically applied.
Google Search Console
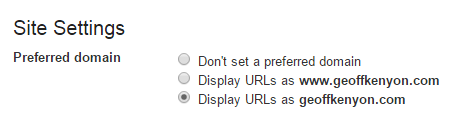
From Google Search Console (Webmaster Tools), you can set the preferred domain (www vs non-www) and you can configure how Google handles parameters. To establish whether Google will show the www or non-www version of your site, click the gear box in the top right and then click site settings and select the preferred domain.
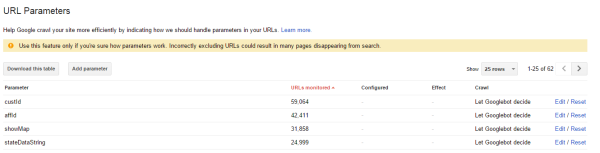
To change how Googlebot crawls your parameters, go to Crawl > URL Parameters >. Then click edit for the parameter you want to configure.
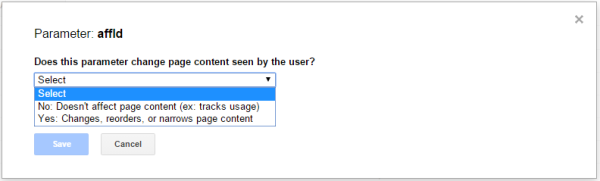
When you click edit, you’ll see a pop up asking whether or not the parameter changes the content of the page. Use this dialog to set up how Google interacts with the URL parameters.
Country Specific Top-Level Domains
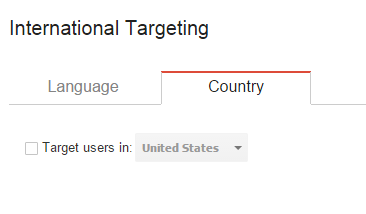
If you have a large company with domains in different countries, it may not be possible to create completely unique content for every page. This can be taken care of Google Webmaster Tools. Navigate to Search Traffic > International Targeting in each of the country domains and select the country of the intended audience for each site.
It’s important to do a few other things to completely differentiate from other country domains. For example, adding local addresses and phone numbers to each country’s site will help clarify which audience is intended. Using a local server and rel=“alternate” hreflang=“x” provides more information to Googlebots about content directed towards specific audiences.
Rel=”prev” / “next”
While paginated content is important for discovery and crawl purposes, these pages can create a significant amount of duplicate content (especially if you have a lot of different categories). You can help Google understand that the pages are part of a sequence using rel=“next” and rel=”prev”. This helps Google understand the relationship between pages, but it won’t inherently prevent duplicate content. As such, you should still use the meta robots noindex command on all paginated pages (excluding the first page).
Hi Geoff, what would you suggest for duplicate content created by product page information, for example, delivery info.
Thanks
Kerry
Hey Kerry,
I wouldn’t be too worried about small amounts of duplicate content (such as the shipping info) as long as majority of the content on the page – the product description, reviews, etc. – are unique.
Very timely article. We’ve just designed a small website that is operating in 4 countries so duplicate content will be an issue. Thanks for the advice.