
Typically when you want to remove a webpage from Google, you can just add the meta robots noindex tag to the <head> section of the webpage. Once this is done you want to get Google to recrawl the webpage in order to pick up the noindex tag and then remove the page from the index. You can jumpstart this process by telling Google to “fetch and render” your newly noindexed URL in Google Search Console. Once they have gone through the fetch and render process, you can then request that Google crawls the URL.
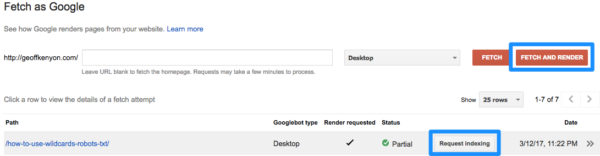
Depending on your site strength and crawl priority, this process can take anywhere from an hour to a week or so.
While this process is great for webpages, it doesn’t actually word for files such as PDFs, word documents, images, etc. The problem is that since a file isn’t a PDF or image isn’t a HTML webpage, there is no <head> section. If you want Google to noindex a PDF, you have to use the x-robots noindex command rather than the meta robots tag.
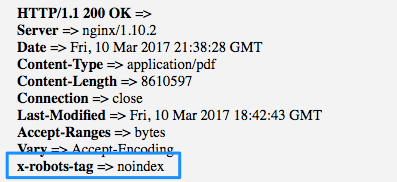
The x-robots command works exactly the same as the meta robots tag but it is inserted into the HTTP headers rather than into the <head> section. As such you can use:
x-robots: noindex x-robots: noindex, nofollow x-robots: noodp x-robots: noarchive x-robots: nosnippet
In order to apply the x-robots noindex tag to you will need to be able to edit your .htaccess file. In order to apply the noindex to all PDF’s on your site, add the following command:
<FilesMatch "\.pdf$"> header set x-robots-tag: noindex </FilesMatch>
If you would like to noindex a single pdf, leverage the following snippet:
<Files guide.pdf> header set x-robots-tag: noindex </Files>
HTTP Header Canonical vs X-Robots for PDFs
If you have a PDF that has links associated with it, noindexing the pdf probably isn’t your best option. Rather, the canonical tag deployed in the HTTP headers would likely serve you better. If you have an HTML page equivalent of the PDF or a landing page to download the PDF, you could canonical the PDF to either of these pages. This strategy would help prevent the loss of link equity by funneling it to an HTML equivalent. While the canonical tag doesn’t guarantee that the PDF is removed from Google’s index, it is what usually happens. Unless an immediate removal of the PDF is required for legal reasons, I usually recommend trying the canonical approach first. Learn how to add the canonical to http headers.
If you are not sure if your file has any links pointing towards it, you can use a tool like a hrefs or SEMrush (aff link) to check.
Preventing PDFs from Getting Indexed with Robots.txt
Disallowing PDFs in the robots.txt file means that Google won’t access your PDF. If you don’t have any PDFs on your site yet and you want to preemptively solve the issue of Google indexing PDFs, This is a solid approach, simply add the following to your robots.txt:
Disallow: /*.pdf
Bonus: Learn more about using wildcards in your robots.txt file
If you already have PDFs on your site and they are already indexed by Google, DO NOT disallow PDFs in your robots.txt file. This will prevent Google from accessing your PDFs but this does not mean that Google will remove the PDF from their index anytime soon. You should instead use the HTTP canonical tag or the x-robots tag.
Using Robots.txt Noindex
While the noindex command is not a support robots.txt function, I have been able to successfully noindex files with this method. If you have no other options and for whatever reason cannot modify your htaccess to properly noindex or canonical your PDFs, you might consider this as a last resort. As it is not officially supported, it might not work, or it could have unpredictable results.
Noindex: /files/download.pdf
How to Remove PDF files From Google’s Index
- Add the x-robots noindex tag to the HTTP headers of the PDF file
- Verify the x-robots noindex tag has been applied
- Tell Googlebot to “Fetch & Render” your PDF in Google Search Console
- Request that Google crawls/indexes your PDF
- Wait for the PDF to drop out of the index